머신러닝을 위한 음성 데이터 수집을 위해 웹 크롤링을 진행하였습니다.
크롬에서 크롤링을 진행할 것이기 때문에 크롤링 전에 크롬 드라이버를 설치하고 가상환경에 셀레니움을 설치하였습니다. (크롬 버전과 동일한 드라이버 설치해야 합니다 !)
크롬 드라이버 다운 : https://googlechromelabs.github.io/chrome-for-testing/
아나콘다에서 셀레니움 설치
- pip install selenium
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support import expected_conditions as EC
import time
import requests
from bs4 import BeautifulSoupchrome_options = Options()
chrome_options.add_experimental_option("detach", True)
위 코드는 Selenium을 사용할 때 Chrome 브라우저의 옵션을 설정하는 예제입니다.
- Options(): Chrome 브라우저의 설정을 변경할 수 있는 클래스
- add_experimental_option("detach", True)는 Chrome이 테스트나 스크립트 실행 후 자동으로 닫히지 않도록 설정한다.(기본적으로 Selenium WebDriver는 테스트 실행 후 브라우저를 종료하지만, "detach" 옵션을 True로 설정하면 브라우저가 종료되지 않고 실행된 상태로 남음)
크롤링 코드
browser = webdriver.Chrome()
browser.get("https://www.fss.or.kr/fss/bbs/B0000203/list.do?menuNo=200686") # 크롤링하고자 하는 웹 url
lst = []
wait = WebDriverWait(browser, 5)
next_page_number = 3
while True:
for i in range(1, 9):
try:
element = wait.until(
EC.presence_of_element_located(
(By.XPATH, f"/html/body/div[2]/div[5]/main/div[2]/div[2]/ul/li[{i}]/a")
)
)
browser.execute_script("arguments[0].click();", element)
print(f'{i}번째 파일')
time.sleep(2)
target_element = wait.until(
EC.presence_of_element_located(
(By.XPATH, "/html/body/div[2]/div[5]/main/div[2]/div[1]/div/div/div/div/div[2]/video")
)
)
audio_url = target_element.get_attribute("src")
lst.append(audio_url)
print(f"Audio URL: {audio_url}")
browser.back()
time.sleep(2)
except Exception as e:
print(f"Error on item {i}: {e}")
try:
if next_page_number == 13:
next_page_number = 3
next_page_button = wait.until(
EC.element_to_be_clickable(
(By.XPATH, f"/html/body/div[2]/div[5]/main/div[2]/div[4]/ul/li[{next_page_number + 1}]/a") # 다음 버튼 클릭
)
)
next_page_button.click() # 다음 페이지로 이동
print(f"------- 다음 페이지로 -------")
time.sleep(3) # 페이지 로딩 대기
next_page_number += 1
except Exception as e:
print("더 이상 페이지가 없습니다.")
break
위 코드는 참고사항이고 자신이 크롤링하고자 하는 웹에서 개발자도구로 요소를 선택하여 알맞은 요소 경로로 설정해야 접근이 가능합니다 !
예를 들어, 저는 위의 코드에서 금융감독원의 영상 데이터들을 수집하려고 했기 때문에 해당 사이트에서 영상 url이 있는 요소를 찾고, (아래 html 코드에서 <a> 태그) 오른쪽의 html 코드에서 우클릭 후 Copy > Copy full XPath로 복사하여 CSS 선택자로 넣어 지정해주었습니다.
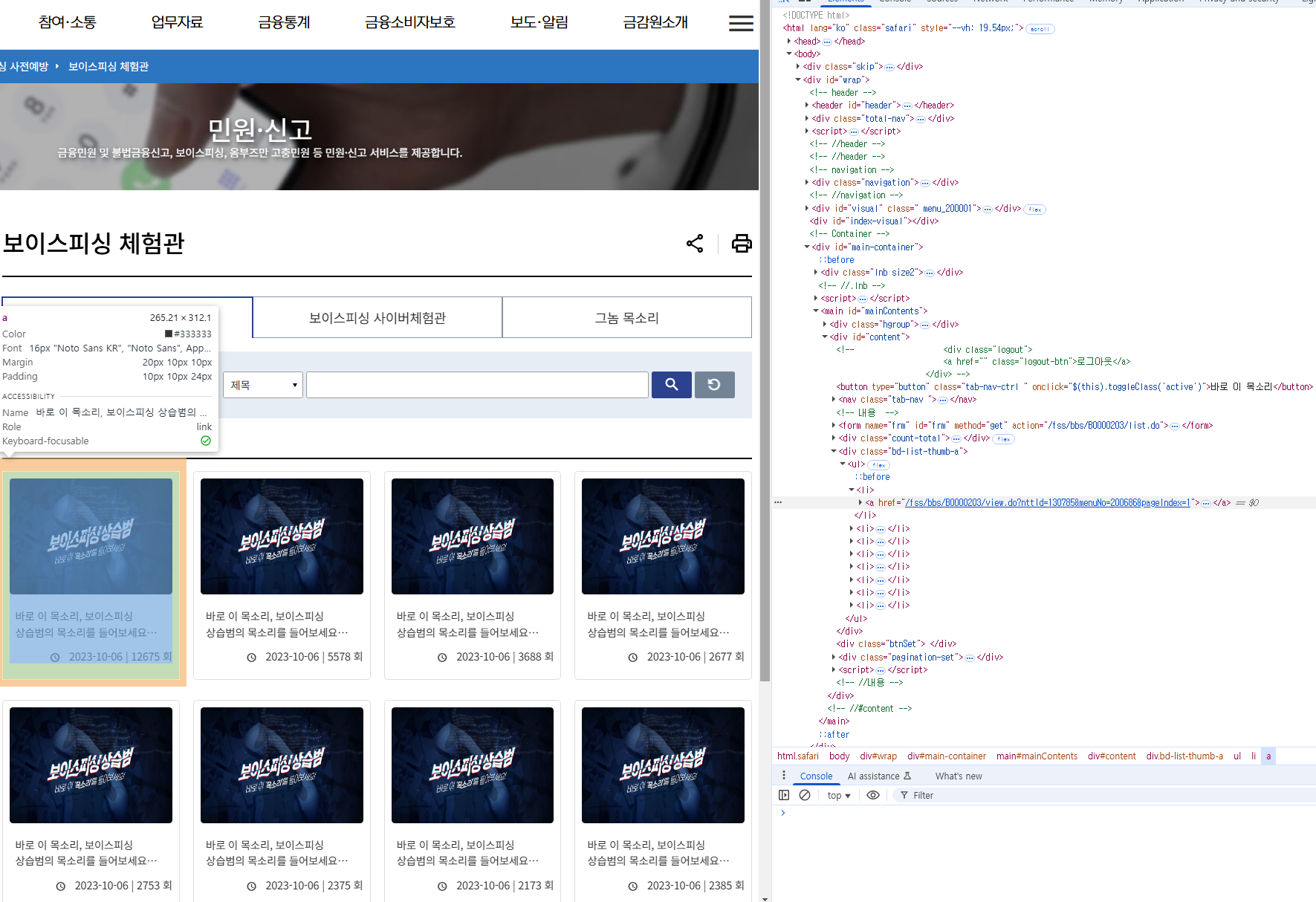

처음에는 CSS 선택자를 사용하여 (By.CSS_SELECTOR, "CSS 선택자")로 진행하였는데 NoSuchElementException이 발생했습니다. 지정한 요소 값을 찾지 못해서 발생하는 에러이며, 이유는 크게 3가지가 있습니다.
- 클래스명으로 접근 시 공백이 있을 경우
- 여러 개의 동일한 클래스명이 있을 경우
- 로딩시간으로 인한 오류 (time.sleep()으로 대기하지 않고 바로 요소에 접근)
하지만 모두 해당하지 않아서 헤매던 중 위 코드와 같이 XPath로 접근하니 정상적으로 잘 돌아갔습니다.
파일 저장
print(lst)
import os
import requests
# 저장할 경로 설정
save_directory = "./Vishing_audio_file"
i = 1
for url in lst:
response = requests.get(url)
file_path = os.path.join(save_directory, f'{i}.mp4') # 파일명 번호로 저장
with open(file_path, 'wb') as file:
file.write(response.content)
i += 1
browser.quit()

'개발 | 프로젝트 > Python' 카테고리의 다른 글
| [Python] execute() 함수 / exec()와의 차이 / cursor (0) | 2025.01.20 |
|---|---|
| [Python] 웹소켓 서버 / 클라이언트 구현 (WebSocket 라이브러리) (1) | 2024.11.27 |
| [Django] 장고의 MVT 패턴 (Model-View-Template) (4) | 2024.10.14 |